2024年是至強(qiáng)的大年
。
先于6月正式發(fā)布的至強(qiáng)? 6700E系列開啟了全新的
、更為簡(jiǎn)潔命名方式:至強(qiáng)? 6能效核
。144核的規(guī)格也意味著英特爾在最
近幾年當(dāng)中首次在核心數(shù)量方面實(shí)現(xiàn)了領(lǐng)先 。而且,這還并不是至強(qiáng)6的最強(qiáng)形態(tài)
,畢竟大家都知道還有個(gè)6900P系列嘛。
9月26日,至強(qiáng)6這個(gè)“最強(qiáng)形態(tài)”終于正式發(fā)布
,主要規(guī)格非常震撼。即使面對(duì)今年內(nèi)晚于自己發(fā)布的其他廠商同級(jí)別CPU
,至強(qiáng)? 6900P的已有規(guī)格也戰(zhàn)力十足。

最強(qiáng)至強(qiáng)能有多強(qiáng)?
英特爾代號(hào)Birch Stream的新一代服務(wù)器平臺(tái)所采用的至強(qiáng)6處理器是分批次發(fā)布的。6月發(fā)布的是代號(hào)Sierra Forest的能效核處理器6700E系列(E后綴即Efficiency Core,能效核的標(biāo)記),目前發(fā)布的是代號(hào)Granite Rapids的性能核6900P系列。今年底和明年初還會(huì)陸續(xù)發(fā)布6900E、6700P,以及6500/6300等。未來(lái)的Intel 18A制造工藝的處理器,如Clearwater Forest,也會(huì)繼續(xù)用于Birch Stream平臺(tái)。
至強(qiáng)6900P是英特爾專為計(jì)算密集型工作負(fù)載設(shè)計(jì)的處理器,也是Granite Rapids的“完全體”
。后綴的“P”意味其采用的是Performance Core
,即
性能核,規(guī)模大、性能強(qiáng);6900的數(shù)字型號(hào)則說(shuō)明其核心配置拉滿——提供了72到128核的多種規(guī)格,TDP有400W和500W兩種,組合成已公開5種型號(hào),顯得比較簡(jiǎn)潔。當(dāng)然
,依照慣例
,云廠商等大客戶還會(huì)有若干定制型號(hào)的。單就內(nèi)核數(shù)量而言
,6900P系列相對(duì)前兩代“Rapids”產(chǎn)品線頂配的56/60(Sapphire Rapids)或64核(Emerald Rapids)直接翻倍!如此巨大的迭代幅度非常罕見(jiàn)
,也難怪英特爾要改命名方式了,由表及里都透著一個(gè)意思:厚積薄發(fā)
、脫胎換骨!
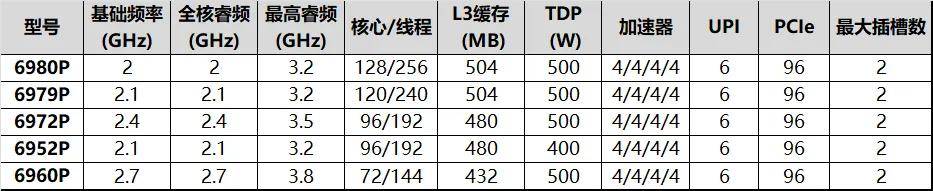
尤為值得一提的是:至強(qiáng)6900P也是業(yè)內(nèi)首款性能核數(shù)量正式“破百”的產(chǎn)品
,其他同級(jí)產(chǎn)品
,不論是x86架構(gòu)還是Arm架構(gòu)都只達(dá)到了96核的水
平。它們的性能核數(shù)量要追平英特爾,起碼得等到下個(gè)季度。隨著內(nèi)核規(guī)模增加,至強(qiáng)6900P的L3緩存達(dá)到了504MB
。為了配合倍增的核數(shù)和顯著提升的算力,至強(qiáng)6900系列的存力也大為增強(qiáng),內(nèi)存帶寬方面不僅支持12通道DDR5 6400;并引入了新型內(nèi)存MR DIMM,把數(shù)據(jù)率大幅提升至8800MT/s,基本內(nèi)存帶寬可以達(dá)到第五代至強(qiáng)可擴(kuò)展處理器的2.3倍。另外,至強(qiáng)6還支持CXL 2.0,尤其是包括Type 3設(shè)備(也就是CXL內(nèi)存),可以進(jìn)一步擴(kuò)展內(nèi)存容量和帶寬。至強(qiáng)6900P的UPI2.0鏈路也有很大改進(jìn)
,速率提升到24GT/s,數(shù)量增加至6條,使得雙路互聯(lián)效率進(jìn)一步提升。結(jié)合內(nèi)核數(shù)量
、內(nèi)存帶寬等方面的全面提升
,至強(qiáng)6900P可以被視作高算力+高存力
平臺(tái)的最強(qiáng)機(jī)頭,不論是科學(xué)計(jì)算,還是AI集群
。根據(jù)已透露的測(cè)試,至強(qiáng)6900P
平臺(tái)的數(shù)據(jù)庫(kù)、科學(xué)計(jì)算等關(guān)鍵應(yīng)用負(fù)載的表現(xiàn)是上一代產(chǎn)品的2.31倍-2.5倍,AI應(yīng)用
性能是其1.83倍-2.4倍不等。


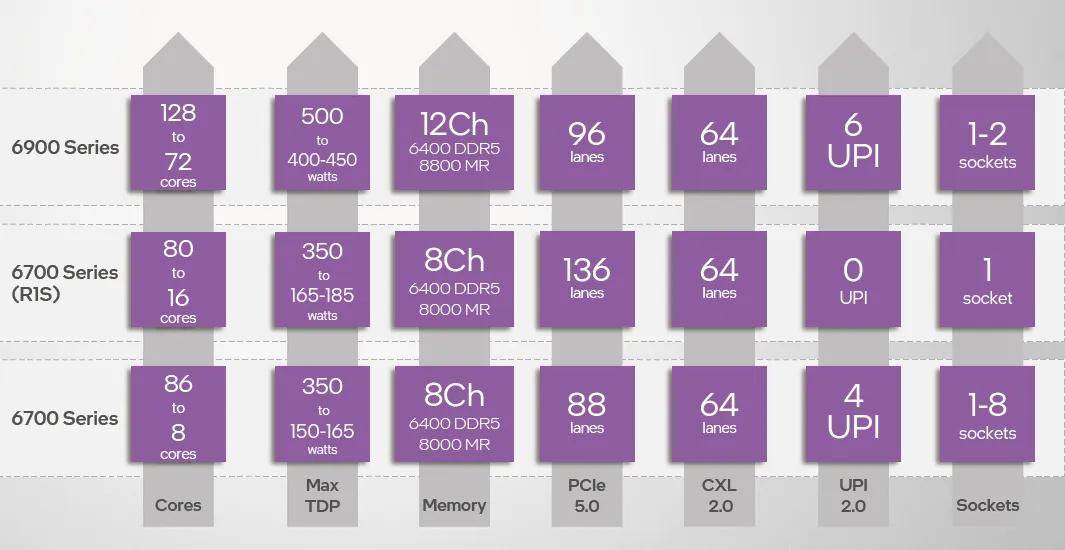
至強(qiáng)6的擴(kuò)展能力也有不小的提升。其中6900系列單插座不論是性能核還是能效核均可提供96通道PCIe 5.0,雙路即可提供192通道PCIe 5.0
。未來(lái)上市的6700系列單路型號(hào)可以提供136通道PCIe 5.0
,雙/多路型號(hào)單插槽也可以提供88通道
。相較而言
,第四、五代至強(qiáng)可擴(kuò)展處理器的PCIe 5.0通道數(shù)量為80
。CXL支持能力方面
,至強(qiáng)6 6900
、6700系列都支持64通道CXL 2.0
。
更多的內(nèi)核
、更多的內(nèi)存通道、更多的PCIe通道需要更大規(guī)模的插座接口支持
。 至強(qiáng)6帶來(lái)了兩種接口:LGA 4710和LGA 7529
。至強(qiáng)6900系列使用面積較大的LGA 7529插座
,提供最強(qiáng)大的內(nèi)存帶寬和擴(kuò)展能力
,是未來(lái)高
性能、高密度服務(wù)器的基礎(chǔ)。至強(qiáng)6700以及未來(lái)的6500/6300系列使用LGA 4710
,尺寸與第四
、五代至強(qiáng)的LGA 4677相仿,內(nèi)存
、PCIe的通道數(shù)相同或相
近,有利于主流服務(wù)器內(nèi)部布局習(xí)慣的延續(xù)性。
改進(jìn)的EUV:Intel 3
核心規(guī)模的飆升首先得益于至強(qiáng)產(chǎn)品線終于獲得EUV光刻機(jī)的加持。在2023年發(fā)布的酷睿Ultra已經(jīng)率先使用了引入EUV的Intel 4制造工藝
。而2024年發(fā)布的至強(qiáng)6則使用了進(jìn)一步改良的Intel 3制造工藝。
2021年7月
,英特爾CEO帕特·基爾辛格公布了“四年五個(gè)制程節(jié)點(diǎn)”(5N4Y)的工藝路線圖
。Intel 3的量產(chǎn)時(shí)間節(jié)點(diǎn)位于2023年底
,節(jié)奏基本符合計(jì)劃
。從基于Intel 4制造工藝的酷睿Ultra的市場(chǎng)表現(xiàn)看
,EUV的加持確實(shí)明顯提升了英特爾處理器的競(jìng)爭(zhēng)力
。至強(qiáng)6所采用的Intel 3制造工藝相對(duì)Intel 4可以規(guī)劃更多的金屬層
、擁有更多細(xì)分版本。

Intel 3在更多的步驟中應(yīng)用EUV光刻
,可以提供更密集的設(shè)計(jì)庫(kù)
、更高的晶體管驅(qū)動(dòng)電流
。Intel 3還有三種變體
,包括3-T
、3-E和3-PT
。Intel 3
、3-T是基本工藝
,主要用于CPU
;3-E是功能擴(kuò)展
;三者都支持TSV;Intel 3的這三種變體與Intel 4相比可以提升18%的
性能功耗比。而3-PT進(jìn)一步增加混合鍵合的支持能力,帶來(lái)了更高的
性能并且易于使用。Intel 3所有四種節(jié)點(diǎn)變體都支持240 nm高
性能和210 nm高密度庫(kù),而Intel 4只支持240 nm高性能庫(kù)。
對(duì)于性能取向,Intel 3針對(duì)高性能運(yùn)算進(jìn)行優(yōu)化,可以支持低電壓(<0.65v)和高壓(>1.3V)運(yùn)行
,且在各電壓下的頻率均高于Intel 4
。

微架構(gòu)大迭代
至強(qiáng)6900P采用的性能核微架構(gòu)代號(hào)Redwood Cove。Redwood Cove也是近年來(lái)英特爾最重要的微架構(gòu)迭代,不但給服務(wù)器產(chǎn)品線帶來(lái)了新名字
,在消費(fèi)類產(chǎn)品線同樣開啟了新的命名序列酷睿Ultra
。
我們先快速回顧一下Redwood Cove的上一代Golden Cove/ Raptor Cove。Golden Cove其實(shí)也是非常重要的迭代,在消費(fèi)類開啟了大小核時(shí)代(第12代酷睿處理器)
,在服務(wù)器上就是第四代至強(qiáng)可擴(kuò)展處理器
。Golden Cove相對(duì)其前代的
微架構(gòu)大幅度提升了前端:指令TLB翻倍
,從128條增加到256條;指令提取帶寬從每周期16字節(jié)翻倍到32字節(jié)
;
解碼器從4路擴(kuò)展到6路
;
微操作緩存從2304條增加到4096條;
其他L1 BTB
、L2 BTB等也有所提升
。
Golden Cove的后端當(dāng)然也有提升,譬如重排序緩沖區(qū)
、分支目標(biāo)緩沖區(qū)也有大概30%左右的提升
,只是相對(duì)前端幅度不那么大
。
Raptor Cove的微架構(gòu)與Golden Cove差異不大 ,表現(xiàn)在實(shí)際產(chǎn)品上主要是緩存的提升
,如基于Raptor Coved的第13代酷睿(Raptor Lake)的每核心L2緩存從12代(Alder Lake)的1.25MB提升到2MB
;第五代至強(qiáng)可擴(kuò)展處理器(Emerald Rapids)和第四代(Sapphire Rapids)每個(gè)核心的L2緩存都是2MB,但前者每個(gè)網(wǎng)格的末級(jí)緩存(Last Level Cache
,也可繼續(xù)俗稱為L(zhǎng)3緩存)從后者的1.875MB猛增到5MB
。
Redwood Cove相對(duì)Golden Cove/ Raptor Cove的最重要變化是:
指令緩存從32KB增加到了16路
、64KB
;
微操作隊(duì)列從144個(gè)條目增加到192個(gè)條目 ;
指令執(zhí)行延遲降低
;
更智能的預(yù)取和改進(jìn)的BPU
;
L2緩存的帶寬有所提升
;
AMX增加FP16支持
。
當(dāng)然
,Redwood Cove還有一個(gè)重大的優(yōu)勢(shì)就是“命好”
,也就是前面提到的EUV制造工藝
。但即使有革命
性的制造工藝加持,至強(qiáng)6性能核也沒(méi)過(guò)分?jǐn)U張每個(gè)內(nèi)核的規(guī)模。就至強(qiáng)6性能核的內(nèi)核而言,每個(gè)網(wǎng)格節(jié)點(diǎn)是一個(gè)P核,每個(gè)P核配置私有的2MB L2緩存,以及共享的4MB 末級(jí)緩存。雖然平均到每個(gè)核的緩存容量并不比上一代至強(qiáng)(Emerald Rapids)多,但勝在總核數(shù)翻倍后。至強(qiáng)6性能核每個(gè)處理器可共享的末級(jí)緩存總?cè)萘恳琅f達(dá)到504MB,遠(yuǎn)超第五代的320MB和第四代的112.5MB。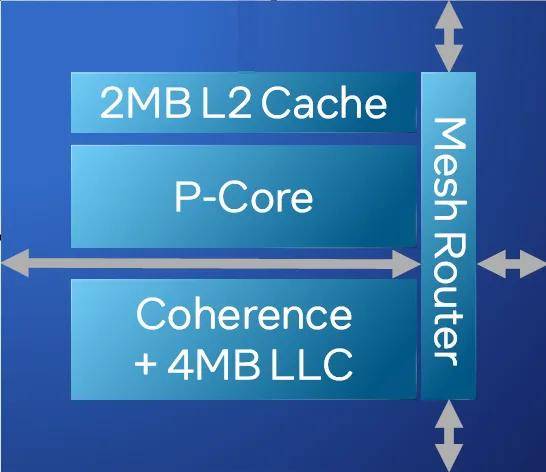
在此也順便提一下至強(qiáng)6能效核的微架構(gòu)Crestmont。這個(gè)微架構(gòu)同樣出現(xiàn)在了酷睿Ultra的能效核當(dāng)中。Crestmont是2或4個(gè)內(nèi)核為一組共享L2緩存。在至強(qiáng)6能效核當(dāng)中,每2或4個(gè)內(nèi)核與4MB的L2緩存(在酷睿Ultra中則為2MB)構(gòu)成一個(gè)模塊,這幾個(gè)內(nèi)核共享頻率和電壓域。這個(gè)模塊對(duì)應(yīng)的網(wǎng)格還擁有可整個(gè)處理器全部?jī)?nèi)核共享的3MB的末級(jí)緩存。換句話說(shuō),雖然至強(qiáng)6能效核的核數(shù)更多,但實(shí)際上網(wǎng)格規(guī)模比至強(qiáng)6性能核小 。

能效核的指令緩存與性能核都是64KB ,但數(shù)據(jù)緩存分別是32KB和48KB。前端的指令解碼器寬度也有差異
,分別為6和8寬。指令亂序執(zhí)行引擎差異較大
,能效核是256條而
性能核是512條。能效核不支持性能核所支持的AVX-512和AMX,這也可以明顯減小矢量運(yùn)算單元的晶體管占用,但代價(jià)是每周期的單精度浮點(diǎn)運(yùn)算次數(shù)有了數(shù)量級(jí)的差異。但能效核也改進(jìn)了AVX2,增加了VNNI的INT8和BF16/FP16快速轉(zhuǎn)換,這樣在處理AI應(yīng)用的時(shí)候表現(xiàn)也還有所改善。另外,其256位加密和1024/2048密鑰也獲得了能效核的支持,確保至強(qiáng)6平臺(tái)的安全水平基本一致。
緩存規(guī)模
、前端寬度以及矢量單元的差異,使得至強(qiáng)6性能核和能效核有不同的定位。早先發(fā)布的至強(qiáng)6能效核更適合微服務(wù)等運(yùn)算強(qiáng)度相對(duì)較輕,可在高核心數(shù)量和規(guī)模擴(kuò)展方面收益的任務(wù),以追求更高的能效、更高的機(jī)架利用率。而現(xiàn)在發(fā)布的至強(qiáng)6性能核更適合大數(shù)據(jù)、建模仿真等計(jì)算密集型和人工智能任務(wù),為高性能優(yōu)化,單顆處理器的功耗直飚500W——當(dāng)然,跟同期發(fā)布的Gaudi AI加速器的新品或類似的加速器產(chǎn)品相比,能耗是應(yīng)有的代價(jià),有能力提升性能上限才是正經(jīng)事。內(nèi)存性能大躍進(jìn)
內(nèi)存(DRAM)的數(shù)據(jù)存儲(chǔ)依賴電容
,這個(gè)特點(diǎn)使其微縮和提速的難度大于晶體管。因此內(nèi)存并沒(méi)有沾摩爾定律的光,帶寬和密度的增長(zhǎng)落后于CPU
、GPU的發(fā)展
。內(nèi)存帶寬滯后于CPU內(nèi)核數(shù)量的增長(zhǎng)導(dǎo)致一個(gè)長(zhǎng)期問(wèn)題:
平均每個(gè)內(nèi)核的內(nèi)存帶寬增長(zhǎng)乏力,甚至出現(xiàn)倒退
。譬如第三代至強(qiáng)可擴(kuò)展處理器內(nèi)核數(shù)28
,內(nèi)存是八通道DDR4 3200
,理論上的內(nèi)存
總帶寬為205GB/s,平均每核7.3GB/s;四代是56或60核,內(nèi)存八通道DDR5 4800,總帶寬307GB/s,平均每核5.5GB/s;五代提升到DDR5 5600,內(nèi)核再增加到64,平均帶寬改進(jìn)甚微。第四、五代至強(qiáng)可擴(kuò)展處理器雖然引入了新一代的DDR5內(nèi)存,但由于內(nèi)核數(shù)量相對(duì)三代翻倍,內(nèi)存帶寬的增長(zhǎng)幅度還是跟不上。同時(shí)期其他廠商的CPU核數(shù)在屢屢躍進(jìn)的過(guò)程當(dāng)中也存在同樣的問(wèn)題。為了彌補(bǔ)內(nèi)存帶寬增長(zhǎng)較慢的問(wèn)題,第四代至強(qiáng)可擴(kuò)展處理器給部分用于科學(xué)計(jì)算的型號(hào)引入了HBM,五代則大幅度增加了末級(jí)緩存的容量,并支持CXL 2.0內(nèi)存擴(kuò)展。
在至強(qiáng)6900P上
,內(nèi)存問(wèn)題終于得到了比較好的解決
。這涉及三個(gè)角度:
1.大容量末級(jí)緩存。前面提到過(guò)
,6900P每個(gè)網(wǎng)格提供4MB L3,
總?cè)萘窟_(dá)到了504MB,分別是四代的4.5倍、五代的1.6倍
。而且
,至強(qiáng)的全網(wǎng)格架構(gòu)使得任意內(nèi)核訪問(wèn)末級(jí)緩存的延遲相比其他廠商的一些產(chǎn)品有更優(yōu)的表現(xiàn)
,例如不需要跨計(jì)算單元而造成延遲劇增
。這種架構(gòu)效率更高的優(yōu)勢(shì)也是至強(qiáng)在核數(shù)曾落后的情況下還能打的有來(lái)有往的關(guān)鍵原因
。
2.DDR5內(nèi)存雙管齊下提升帶寬。至強(qiáng)6900系列支持12通道DDR5 6400
,
總帶寬可以達(dá)到614GB/s,
平均每核的帶寬大致還有5GB/s的水平。6900P還支持新型內(nèi)存MRDIMM
,頻率提升至8800MT/s
,
總帶寬達(dá)到了845GB/s,
平均每核6.6GB/s,也明顯超過(guò)了前兩代產(chǎn)品,大幅度逆轉(zhuǎn)了內(nèi)核數(shù)量增加、
平均內(nèi)存帶寬不升反降的問(wèn)題。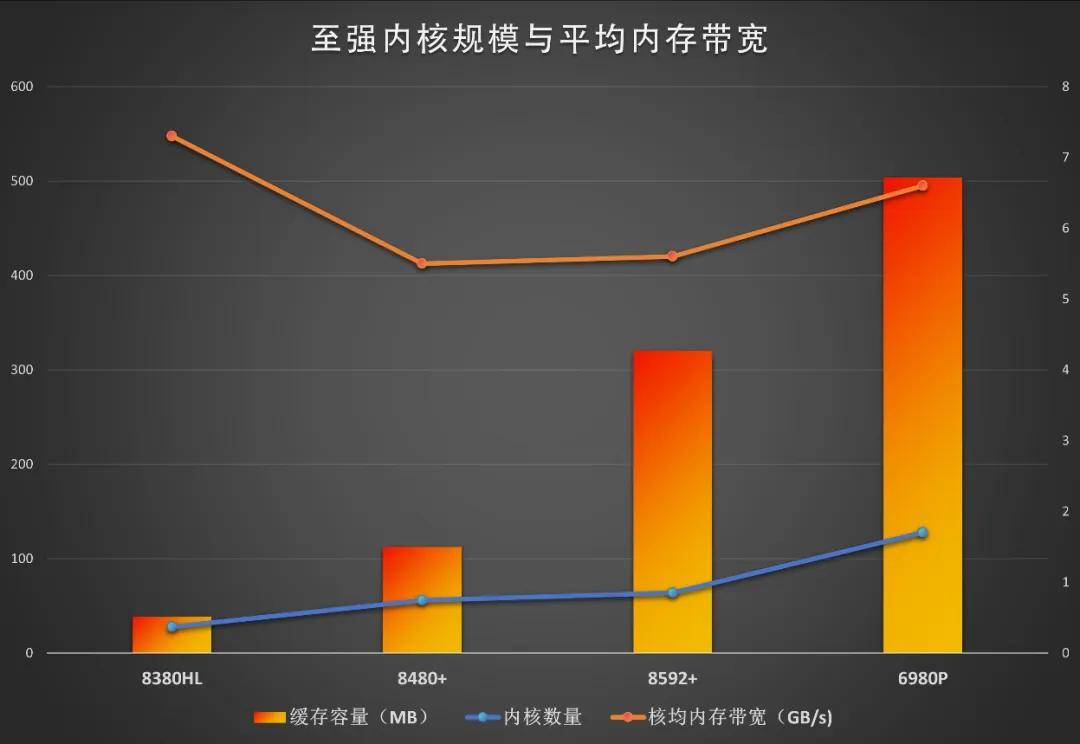
MR(Multiplexed Rank)DIMM打開了DDR內(nèi)存性能提升的新方向。DRAM通常由1到2個(gè)Rank組成,每個(gè)Rank的位寬為64位,如果考慮ECC,那就會(huì)有72或80位
,但有效的數(shù)據(jù)是64位
。消費(fèi)類內(nèi)存(UDIMM)可能只有1個(gè)Rank(顆粒數(shù)量較少的情況下),但追求大容量的服務(wù)器內(nèi)存(RDIMM)基本上都至少有2個(gè)Rank
。在以往的內(nèi)存模式當(dāng)中,一次只讀取一個(gè)Rank的數(shù)據(jù)
,另一個(gè)Rank暫時(shí)閑置時(shí)可以做刷新操作
,以保持?jǐn)?shù)據(jù)——這種輪流讀取
、刷新Rank的特點(diǎn)延續(xù)了多年
。MRDIMM設(shè)計(jì)了一個(gè)數(shù)據(jù)緩沖區(qū)
,通過(guò)將兩個(gè)內(nèi)存Rank分別讀入這個(gè)緩沖區(qū)
,再?gòu)木彌_區(qū)一次
性傳輸?shù)紺PU的內(nèi)存控制器,由此實(shí)現(xiàn)了帶寬翻倍
。第一代DDR5 MRDIMM的目標(biāo)速率為8800 MT/s
,其實(shí)每個(gè)Rank只相當(dāng)于4400MT/s?div id="jfovm50" class="index-wrap">,F(xiàn)在DDR5 6400已經(jīng)開始普及,因此MR DIMM的第二階段目標(biāo)是達(dá)到12800 MT/s
,預(yù)計(jì)在2030年代的三代會(huì)提升至17600 MT/s。
3.CXL 內(nèi)存擴(kuò)展。第四代至強(qiáng)可擴(kuò)展處理器開始引入CXL支持,當(dāng)時(shí)是1.1版本
,暫時(shí)也沒(méi)有公開支持Type 3設(shè)備(也就是CXL內(nèi)存)
。從第五代開始正式引入了CXL 2.0
,包括Type 3,可以幫助擴(kuò)展內(nèi)存容量和帶寬
。在至強(qiáng)6上
,CXL設(shè)備的應(yīng)用將更為普及,關(guān)鍵的CXL2.0標(biāo)準(zhǔn)設(shè)備
,以及后向兼容的CXL1.1設(shè)備
,預(yù)計(jì)都會(huì)陸續(xù)涌現(xiàn)。
這里重點(diǎn)說(shuō)一下CXL內(nèi)存的優(yōu)勢(shì)
。CXL2.0支持鏈路分叉
,使一個(gè)主機(jī)端口可以對(duì)接多個(gè)設(shè)備,而且提供更強(qiáng)的CXL內(nèi)存分層支持
,可實(shí)現(xiàn)容量和帶寬擴(kuò)展。至強(qiáng)6支持3種CXL內(nèi)存擴(kuò)展模式:CXL Numa Node
、CXL Hetero Interleaved
、Flat Memory
。

在CXL Numa Node模式下
,系統(tǒng)的標(biāo)準(zhǔn)內(nèi)存和CXL擴(kuò)展內(nèi)存被視為兩個(gè)
獨(dú)立的Numa節(jié)點(diǎn)進(jìn)行控制。每個(gè)Numa節(jié)點(diǎn)都有自己的內(nèi)存地址空間,系統(tǒng)軟件或應(yīng)用程序可以將任務(wù)分配到不同的Numa節(jié)點(diǎn)
,從而優(yōu)化內(nèi)存的使用。CXL Numa Node模式適用于需要精細(xì)內(nèi)存管理的應(yīng)用
,可以通過(guò)操作系統(tǒng)
、虛擬機(jī)管理程序(Hypervisor)或應(yīng)用程序本身來(lái)輔助分層管理內(nèi)存
。
Hetero Interleaved(異構(gòu)交織)模式通過(guò)將系統(tǒng)的標(biāo)準(zhǔn)內(nèi)存和CXL內(nèi)存混合在一起
,形成一個(gè)統(tǒng)一的Numa節(jié)點(diǎn)
。每個(gè)內(nèi)存地址空間中的數(shù)據(jù)可以交替存儲(chǔ)在DRAM和CXL內(nèi)存中
,從而均衡內(nèi)存帶寬,減少延遲
。異構(gòu)交織模式適用于對(duì)內(nèi)存帶寬有高需求的應(yīng)用,特別是當(dāng)需要將DRAM和CXL內(nèi)存結(jié)合使用時(shí)
。此模式只有在配備
性能核的至強(qiáng)6700P、6900P上才支持。假設(shè)將每顆至強(qiáng)6900P的64通道CXL用滿,可以額外增加256GB/s的內(nèi)存帶寬,單處理器就可以實(shí)現(xiàn)TB級(jí)的內(nèi)存帶寬,還是相當(dāng)可觀的。Flat Memory(平面內(nèi)存)模式下 ,CXL內(nèi)存和標(biāo)準(zhǔn)內(nèi)存被視為單一的內(nèi)存層
,操作系統(tǒng)可以直接訪問(wèn)統(tǒng)一的內(nèi)存地址空間
。硬件輔助的分層管理可以確保常用數(shù)據(jù)優(yōu)先存儲(chǔ)在標(biāo)準(zhǔn)內(nèi)存中
,次要數(shù)據(jù)存儲(chǔ)在CXL內(nèi)存中
,從而最大限度地提升內(nèi)存使用效率
。
平面內(nèi)存模式最大的價(jià)值在于無(wú)需修改軟件即可利用CXL內(nèi)存擴(kuò)展,而且這種模式適用于所有的至強(qiáng)6處理器 。但平面內(nèi)存模式要求標(biāo)準(zhǔn)內(nèi)存和CXL內(nèi)存是1:1配置,這略為限制了硬件采辦